
Inhalte
Einleitung
In den letzten Jahren haben sich große Sprachmodelle, auch bekannt als Large Language Models (LLMs), zu einem zentralen Bestandteil moderner künstlicher Intelligenz entwickelt.
Diese Modelle sind in der Lage, komplexe Muster in Sprachdaten zu erkennen und eine Vielzahl von sprachbezogenen Aufgaben zu erfüllen, von der Textgenerierung über die Sprachübersetzung bis hin zur Entwicklung neuer KI-Anwendungen. Kurzum: LLMs revolutionieren die Art und Weise, wie wir mit Technologie interagieren und Informationen verarbeiten.
In der Praxis denken wir aktuell beinahe ausschließlich an die großen Sprachmodelle aus den USA und Europa wie etwa die GPT-Reihe von OpenAI, Claude von Anthropic oder LLama von Meta. Diese Modelle haben zweifellos bedeutende Fortschritte gemacht und setzen weltweit Maßstäbe. Doch auch in anderen Regionen der Welt wir die Entwicklung von LLMs in Windeseile vorangetrieben. Ob in Asien, dem Nahen Osten, Afrika oder Lateinamerika, beinahe überall entstehen innovative Modelle, die u.a. spezifische lokale Bedürfnisse und Sprachen berücksichtigen.
Grund genug, einmal über den Tellerrand zu schauen und uns anzusehen, welche großen Sprachmodelle in verschiedenen Regionen entwickelt wurden, welche besonderen Herausforderungen und Chancen sie mit sich bringen und wie sie zur globalen technologischen Entwicklung beitragen.
Beispiele für KI-Modelle außerhalb der USA und Europa
Auch außerhalb der USA und Europa werden bei der Entwicklung großer Sprachmodelle (LLMs) bedeutende Fortschritte gemacht. Hier sind einige bemerkenswerte Beispiele für LLMs aus verschiedenen Regionen, die die Vielfalt und Innovationskraft der globalen KI-Landschaft widerspiegeln.
China
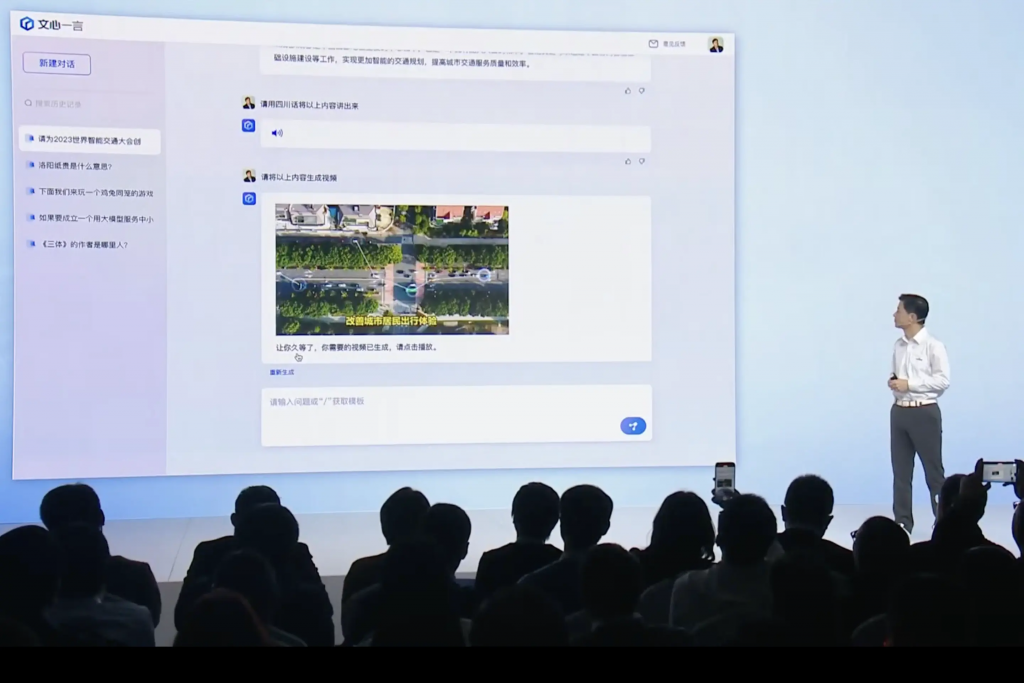
ERNIE Bot 4.0 (Baidu)
Baidu, ein führendes chinesisches Technologieunternehmen, hat mit ERNIE Bot 4.0 eines der fortschrittlichsten Sprachmodelle entwickelt. Diese Version zeigt erhebliche Verbesserungen gegenüber ihren Vorgängern und wird in einer Vielzahl von Anwendungen eingesetzt, darunter intelligente Assistenten und Content-Generierung.
MOSS (Tsinghua University)
Ein weiteres großes KI-Modell aus China ist MOSS, entwickelt von der Tsinghua University. Dieses Modell wurde entwickelt, um eine Vielzahl von Sprachen zu unterstützen und bietet Funktionen in der natürlichen Sprachverarbeitung. MOSS ist eines von vielen Beispielen für Chinas Engagement in der akademischen Forschung und Innovation im Bereich der KI.
Israel
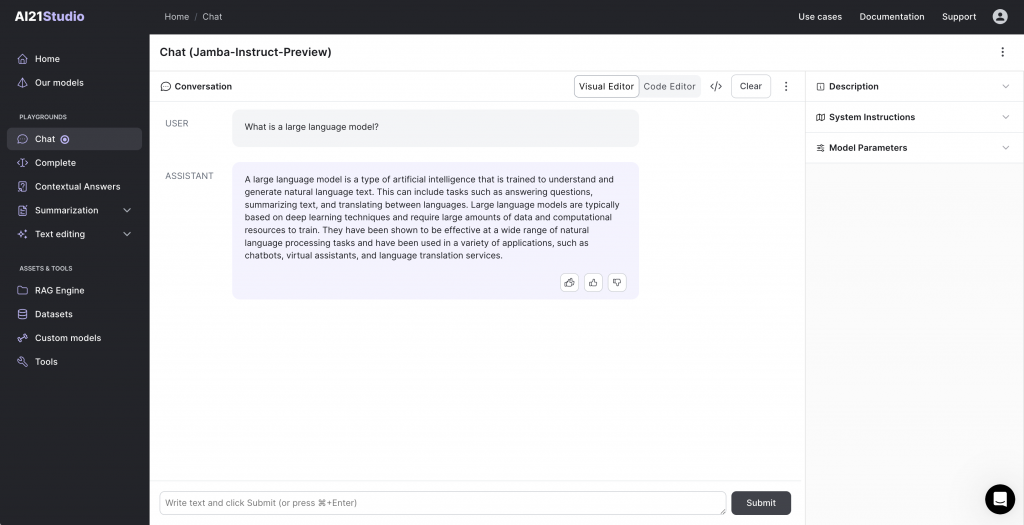
Jamba (AI21 Labs)
AI21 Labs aus Israel hat kürzlich Jamba eingeführt, ein innovatives Sprachmodell, das die Stärken von Mamba- und Transformer-Architekturen kombiniert. Jamba kann bis zu 256.000 Token verarbeiten und erreicht etwa die dreifache Durchsatzrate im Vergleich zu herkömmlichen Modellen. Es verwendet eine Mixture-of-Experts (MoE) Schicht, um die Effizienz zu erhöhen, indem es nur 12 Milliarden der verfügbaren 52 Milliarden Parameter während der Inference nutzt.
Südkorea
HyperCLOVA (Naver)
Naver, das führende Internetunternehmen Südkoreas, hat mit HyperCLOVA ein großes Sprachmodell entwickelt, das speziell auf die koreanische Sprache und den lokalen Markt ausgerichtet ist. HyperCLOVA wird in einer Vielzahl von Anwendungen genutzt, von Chatbots bis hin zu Sprachassistenzsystemen.

Japan
Fugaku-LLM (RIKEN)
Das RIKEN Center for Computational Science hat Fugaku-LLM entwickelt, ein Sprachmodell, das auf dem leistungsstarken Supercomputer Fugaku trainiert wurde. Fugaku-LLM zeigt erweiterte Fähigkeiten in der Verarbeitung der japanischen Sprache und wird sowohl in der Forschung als auch in kommerziellen Anwendungen eingesetzt.

Indien
Airavata (AI4Bharat)
Airavata, entwickelt von AI4Bharat, ist ein neues Sprachmodell, das speziell für die Hindi-Sprache optimiert ist. Dieses Modell basiert auf dem OpenHathi-Modell und wurde mithilfe von IndicTrans2, einem fortschrittlichen maschinellen Übersetzungsmodell für indische Sprachen, feinabgestimmt. Airavata adressiert dabei in der natürlichen Sprachverarbeitung die spezifischen Bedürfnisse der Hindi-sprachigen Bevölkerung.

Russland
GigaChat (Sberbank)
Sberbank hat kürzlich GigaChat eingeführt, ein auf ruGPT-4.5 basierendes Sprachmodell, das für den russischen Kontext optimiert ist. GigaChat hebt sich durch seine Fähigkeit zur Text- und Bildgenerierung ab, was eine Vielzahl an möglichen Anwendungsfeldern eröffnet. Es wird für Finanzberatung und Kundendienstautomatisierung eingesetzt und bietet eine API, die die Integration in verschiedene Geschäftsanwendungen erleichtert.
Vereinigte Arabische Emirate
Falcon (Technology Innovation Institute)
Das Falcon-Modell wurde vom Technology Innovation Institute in Abu Dhabi entwickelt und ist eines der leistungsfähigsten Open-Source-LLMs mit 180 Milliarden Parametern. Falcon-Modelle sind auf dem RefinedWeb-Datensatz trainiert, der qualitativ hochwertige Webdaten umfasst und dadurch in verschiedenen NLP-Aufgaben herausragende Leistungen zeigt. Falcon unterstützt über 100 Sprachen und wird in Anwendungen wie Inhaltsgenerierung, Sprachübersetzung, Fragebeantwortung und Sentimentanalyse eingesetzt. Die Modelle sind unter der Apache 2.0-Lizenz verfügbar.

Relevanz der geographischen Herkunft von KI-Modellen
Die geografische Herkunft von LLMs spielt eine nicht unbedeutende Rolle in ihrer Entwicklung und Anwendung. Kulturelle, sprachliche und technologische Unterschiede prägen die Art und Weise, wie diese Modelle trainiert werden und welche Aufgaben sie erfüllen können. In diesem Abschnitt beleuchten wir, warum es wichtig ist, die geografische Herkunft von LLMs zu berücksichtigen.
Kulturelle und sprachliche Vielfalt
Eines der wichtigsten Argumente für die Entwicklung lokaler LLMs ist die Berücksichtigung der kulturellen und sprachlichen Vielfalt. Viele global verwendete KI-Modelle sind auf die englische Sprache und westliche kulturelle Kontexte ausgerichtet. Lokale Modelle hingegen können spezifische Sprachmerkmale und kulturelle Nuancen besser erfassen. In Indien beispielsweise gibt es eine enorme sprachliche Vielfalt mit Hunderten von Sprachen und Dialekten. Ein Modell das speziell für diese Vielfalt entwickelt wurde, kann diese Sprachen besser verstehen und verarbeiten als ein generisches Modell, das hauptsächlich auf Englisch trainiert wurde.
Technologische Souveränität
Ein weiterer wichtiger Aspekt ist die technologische Souveränität. Länder und Regionen, die ihre eigenen LLMs entwickeln, reduzieren ihre Abhängigkeit von westlichen Technologien und stärken ihre eigene Innovationskraft. Dies ist besonders in Ländern wie China und Russland zu beobachten, wo staatlich unterstützte Initiativen die Entwicklung eigener Technologien vorantreiben. Solche Bestrebungen zielen darauf ab, unabhängige und leistungsfähige Alternativen zu westlichen Modellen zu schaffen.
Wirtschaftliche und strategische Bedeutung
Die Entwicklung eigener LLMs hat auch eine wirtschaftliche und strategische Bedeutung. Lokale Sprachmodelle können dazu beitragen, den digitalen Wandel in verschiedenen Sektoren voranzutreiben, von der Gesundheitsversorgung über das Bildungswesen bis hin zum Finanzsektor. Sowohl Technologieunternehmen als auch Start-ups investieren intensiv in die Entwicklung und Anwendung von LLMs, um wettbewerbsfähig zu bleiben und neue Märkte zu erschließen.
Zusammengefasst lässt sich sagen, dass die geografische Herkunft von LLMs eine wichtige Rolle bei ihrer Entwicklung und Anwendung spielt. Lokale Modelle können kulturelle und sprachliche Besonderheiten besser berücksichtigen, zur technologischen Souveränität beitragen und wirtschaftliche und strategische Vorteile bieten. In einer zunehmend globalisierten Welt ist es entscheidend, diese Vielfalt zu fördern und zu nutzen, um die Potenziale von LLMs voll auszuschöpfen.
Fazit
Die Entwicklungen im Bereich der großen KI-Modelle außerhalb der USA und Europa zeigen deutlich, dass Innovation und Fortschritt in der künstlichen Intelligenz ein globales Phänomen sind. Diese Modelle tragen zur technologischen, wirtschaftlichen und kulturellen Entwicklung in ihren jeweiligen Regionen bei und unterstreichen die Bedeutung einer diversifizierten und inklusiven Herangehensweise an die KI-Entwicklung.
Zusammenfassung der wichtigsten Punkte
Die Beispiele aus China, Israel, Südkorea, Japan, Indien, Russland und den Vereinigten Arabischen Emiraten verdeutlichen, wie LLMs auf lokale Sprachen und kulturelle Kontexte zugeschnitten werden. Modelle wie die oben erwähnten demonstrieren die Leistungsfähigkeit und Anpassungsfähigkeit, die durch die Fokussierung auf regionale Besonderheiten erreicht werden können. Diese Entwicklungen tragen nicht nur zur technologischen Souveränität der jeweiligen Länder bei, sondern bieten auch maßgeschneiderte Lösungen für lokale Herausforderungen und Bedürfnisse.
Ausblick in die Zukunft von KI-Modellen
Die zukünftige Entwicklung von LLMs wird voraussichtlich noch vielfältiger und globaler werden. Die Zusammenarbeit zwischen verschiedenen Ländern und Forschungseinrichtungen könnte zu noch leistungsfähigeren und vielseitigeren Modellen führen. Die Integration kultureller und sprachlicher Vielfalt in die Entwicklung von LLMs wird nicht nur die Technologie selbst bereichern, sondern auch ihre Anwendungen und die Art und Weise, wie wir mit ihr interagieren. Auch Unternehmen werden sich bei der Integration von KI zunehmend Gedanken zur Wahl der richtigen LLM machen müssen.
Es ist erstrebenswert, dass die globale Gemeinschaft die Bedeutung und den Wert von LLMs außerhalb der westlichen Welt erkennt und fördert. Dies wird nicht nur zur technologischen Weiterentwicklung beitragen, sondern auch zu einer gerechteren und inklusiveren globalen Innovationslandschaft. Die Beispiele in diesem Artikel zeigen, dass es bereits bedeutende Fortschritte gibt und dass die Zukunft der LLMs vielversprechend ist.