
Understanding what it means to "train" an AI model
Many non-tech individuals have a wrong believe:
They have internal documents and want to chat with it. They ask us: "How to Train AI model with business data?"
For this you would use existing large language models (LLMs) such as ChatGPT or Deepseek!You wouldn't train your own AI model.You would combine the LLM with Retrieval-augmented generation (RAG) to chat with internal documents. For putting data to work without training, see using internal data with AI and enterprise knowledge systems.
However, there are many other use cases that need actual AI model training. For real-world examples, see our AI model examples in 2025. Examples: Predicting diseases for patients or determining necessary maintenance for airplane engines.
Recently I talked with someone doing fraud prediction for MercadoLibre. MercadoLibre is the biggest payment processor in Latin America, processing billions of dollars.They train AI models to prevent fraud before it can happen. All live, 24/7, hardcore machine learning! 😁
All examples from this blog article how to train AI model with business data use supervised learning approaches. A model is trained using labeled data, meaning each input is paired with the correct output.
Prerequisites
- Have data available ✅
- Have an objective to predict ✅
- Have someone who can train a model ✅
hint: we at Dentro do this for our customers!
Step 1: Data Exploration
Importance of Data Exploration before Training
Data exploration is important for training AI models with business data. It involves assessing data quality, structure, and potential insights.
Sources like Heavy AI emphasize the importance of identifying missing values, outliers, and characteristic distributions. This sets the foundation for effective model training.
Or as Hamel Husain always puts it: "Look at your data!"
Techniques for Effective Data Visualization
Using Python and Pandas for Data Handling
Python's pandas library is indispensable for data manipulation and cleaning. Its robust features streamline data handling, ensuring datasets are primed for visualization and subsequent training.
Tools like Matplotlib are extremely useful to visualize the data and understand it!
How to Train AI model Step 1 done.

Step 2: Creating Datasets
Determining Key Features for Prediction
Determining which features hold predictive power is critical. It requires a blend of domain expertise and data analysis. Prioritize impactful attributes, thereby honing the model's focus on valuable insights.
To predict a disease, important features of a patient might be:
- age
- weight
- height
The eye color and the name of the patient might be unimportant to predict a disease. Or you realize that the name is important indeed. Perhaps people with certain names come from certain cultures that are more prone to diseases than others.
Deciding which features are important is called "feature engineering".Often you also create new features that are computed based on the existing data. E.g.:
- how many days passed since the last visit to the doctor?
- does the patient live in a certain area that has lots of pollution? If yes, perhaps add the feature "polluted_area=True".
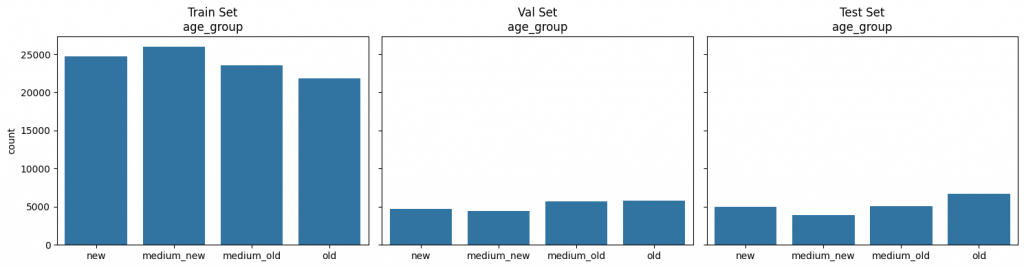
Splitting the data into Training, Validation and Testing Set
Typically you split the data into 3 datasets:
- Train set
used for training the model
- 70% of available data
Validation set
- every X training iterations of model training, the model is evaluated based on the val set. This is to adapt hyperparameters, and stopping early to prevent overfitting.
- 15% of available data
Testing set
- After all training is finished using the train and val set, we have an AI model. We use the Test set to do a final evaluation of its performance
- 15% of available data
How you split them is crucial if when you think about how to Train AI model...
Stratification
It's important that the data in each dataset split is distinct. The same entry should only be part of a single set. If not, the model can just memorize data. It sees a fraudulent transaction in the train set with the correct prediction. When it sees the same fraudulent transaction in the test set, it just remembers from the train set that it was fraudulent. This would be one form of data leakage (bad).
On the other hand, the data has to be similar in all splits. Imagine we only have young patients in the train set, and only old patients in the test set. When predicting on the test set, the AI model will say "they're healthy" far too often. Because it's used to work with young patients.
That's why we need to do something called stratification.
First we create "stratification" groups based on features. Then we make sure that in each dataset split, we have the similar amount of groups. That way all datasets have similar but distinct data! Perfect to train some useful AI models 👌🏼
Step 3: Data Pre-processing
How to Train AI model with business data?
We need to transform the available data into numbers!These numbers can then be used to actually train an AI model.
You can decide on whether to scale your data. The performance of some AI models is influenced by scaling, some aren't. Scaling can influence the interpretability for some models, for others not.
This step for knowing how to train AI model is not that involved. So we'll leave it as it is.

Step 4 of How to Train AI model: Model Training
In the previous steps you thought already about which ML models are suitable for your data:
- Do you have a small, medium-sized or large dataset?
- Is your prediction task a classification, regression, sequence prediction, etc. ?
- Do you mainly have numerical data, textual data, audio, images etc.?
Based on this you choose to train 2 AI models:
- Base Model
A simpler model that's easier to implement. E.g. logistic regression
More Sophisticated model
- A more complicated model that should yield better results. E.g. gradient boost
The base models sets the base line for performance. If the more sophisticated model can't perform significantly better than the base model, then just use the simpler model. Simple is always better, it's easier to understand.
Hyperparameter tuning
We can train the model once, and see the performance. If we want to improve it, we can train it again with different hyperparameters. E.g. different learning rate, number of epochs etc.
Now we can do this manually, or automatically. If done automatically, it's called "Hyperparameter tuning".We just train the model a 100 hundred times with different hyperparameters and only keep the best performing model!
Main 2 hyperparameter tuning algorithms:
- Grid based
define a set of inputs for each hyperparameter, and train with every possible combination of all inputs
- Yields stable results
Random search
- Define an area "from / to" for each hyperparameter, and randomly try out combination within the defined area.
- Results can fluctuate, very poor to very good
Now you know almost all steps for how to Train AI model!

Step 5: Evaluating AI Model Performance
For this section, let's use a binary binary classification tasks for explanation.Imagine an AI model deciding whether an **airplane engine **needs to be changed:
- The model predicts: Change or Don't Change
- We compare this with actual data: Should Change or Shouldn't Change
When evaluating AI models, especially classification tasks, we use a tool called the confusion matrix. It's very useful for knowing how to Train AI model.
Let's break it down:
- The confusion matrix helps us compare the model's predictions with actual results
- It's particularly useful for (binary) classification tasks (e.g. yes/no decisions)
Here's a simple confusion matrix:

What these mean:
- True Positive (TP): Model says change, and it should be changed
- True Negative (TN): Model says don't change, and it shouldn't be changed
- False Positive (FP): Model says change, but it shouldn't be changed
- False Negative (FN): Model says don't change, but it should be changed
From this matrix, we can calculate important metrics:
- Accuracy: How many predictions were correct overall?
(TP + TN) / (TP + TN + FP + FN)
Recall: Of all engines that should be changed, how many did we catch?
- TP / (TP + FN)
Precision: Of all engines we said to change, how many actually needed it?
- TP / (TP + FP)
F1 Score: A balance between precision and recall
Read more theory about precision and recall on Wikipedia.
Understand what to optimize for
You want to know how to Train AI model?Then it's important to understand what you want to optimize for.
Let's take the **example of the airplane engine. **Let's say 5% of all airplane engines should be changed. This is a highly imbalanced dataset.
If we would just have a model that says, hey, no engine at all has to be changed, then the accuracy would be 95%. This is great, but doesn't help us. Because all the ones that should be changed are not changed. And all those 5% airplanes crash 😬
In the airplane case, we should probably focus to catch all the engines that actually have to be changed. So we want to have 100% of recall. 100% recall means all engines that should be changed, are also predicted to be changed -> no False Negatives!
Now, we could have a model that just says all the engines have to be changed. We have 100% of recall.But all the other engines are also changed which don't need a change.I mean, we don't need a model for that, right?
In this case, we should probably focus on 100% recall and very high accuracy at the same time. Or very high precision at the same time, but optimized for recall.
Let's take another example: **emails.**Here we have to classify whether an email is spam or not. The important thing is that we don't put legit emails into the spam folder. Now, here it's the opposite, we don't need a very high recall. But we need to make sure that all emails that are classified as spam, are actually spam. We need to optimize for precision!
Based on the data you have, you have to optimize for certain metrics and evaluate your models.

Iterating and Improving the AI Model
Now you have the results. Either superb performance, or bad / average performance. What's the next step regarding how to train AI model?
Amazing performance
You have amazing results: 99% accuracy and 99% F1 score.You're excited about the great job you did!Finally you know how to train AI model.
But unfortunately, this typically points to data leakage or overfitting. You have to walk through all your pipeline and see where the data leakage comes from.
Perhaps in the dataset you mark a transaction as fraudulent. But you have also another feature which says something similar. E.g. when did the last fraud happen? (when_did_last_fraud_happen=2025-02-02).But you code it wrong. This feature is the same day as when a transaction happened (date_of_transaction=2025-02-02), instead of the last time the fraud happened.
You only remove from the dataset that it was a fraudulent transaction.But you keep the value that says when the last fraud happened, which is the same day as the transaction! ⚠️
The model sees the that last fraudulent transaction happened on the same day as the transaction.Based on this the model knows that it's fraudulent.The performance is 99%, just because your dataset doesn't reflect the real world.You don't know how to train AI model.
Bad / Average performance
If your model performance is not satisfactory, you have to go back to the previous steps and see where you can improve it.
This is the art of training an AI model.As you have a million of options, and you can't try them all. The AI engineer knows where it makes most sense to do something.He knows how to train AI model.
Examples for improvements:
- Use cross validation for dataset creation,
- Use a different Scaler when pre-processing the data. E.g. Use a RobustScaler instead of a StandardScaler to handle outliers better
- You might use a different ML model. At the beginning you thought the time series model is an overkill. Now you think maybe it makes sense.
- Maybe you want to expand your hyperparameter tuning
- Maybe you go to the very beginning when you understand the data. Perhaps you misunderstood which features are important, which are not, and you have to change this.
- Read this blog article again about how to train AI model with business data.
Data visualization
Visualize at every step!
Look at your data!
Plot which features of your dataset are most important for your models. This is called "feature importance". It can help you to find data leakage, or identify unnecessary features.
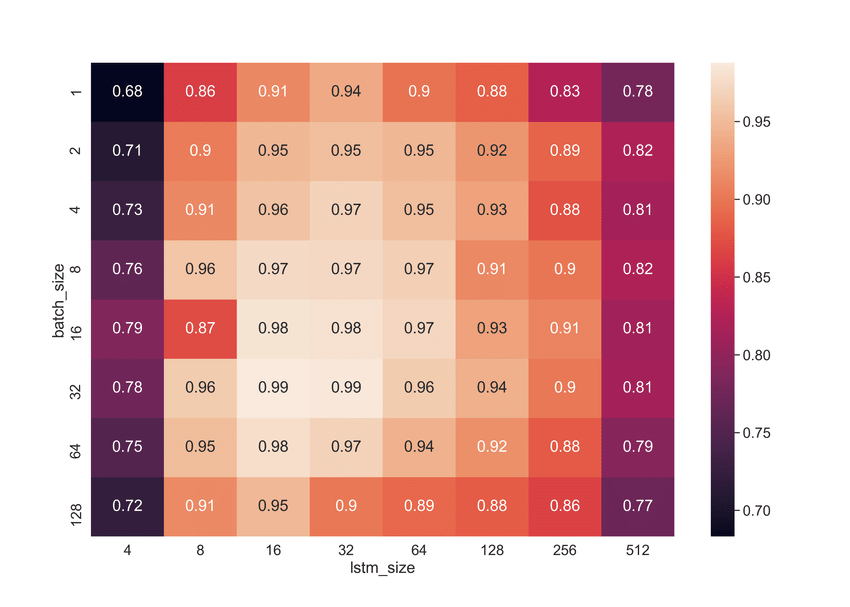
Compare performance of different models with a heatmap. This way you see at a glance which configuration and models work best.
Final Thoughts on AI Model Training for Business
Often you don't need to train a model from scratch to implement AI in your company.
Now you know how to approach it! 😉
These were the 5 popular steps on How to Train AI model with Business Data.
We're pushing the boundaries of what's possible with AI.Stay up to date with Dentro by following our newsletter!
We use "How to Train AI model" throughout the article not because we're idiots, but to push the keyword density and our SEO ranking 😅. In that sense, now you know how to train AI model!