
TL;DR: Ihre Website rankt vielleicht bei Google, bleibt für KI-Assistenten wie ChatGPT oder DentroChat aber unsichtbar – weil die meisten KI-Crawler kein JavaScript ausführen und nur das rohe HTML sehen. Die Lösung: Server-Side Rendering oder Pre-Rendering einsetzen, Ihre Seiten mit „Seitenquelltext anzeigen" oder deaktiviertem JavaScript prüfen und strukturierte Daten ergänzen, damit KI-Systeme Ihre Inhalte richtig verstehen.
Warum ein KI-Crawler andere Dinge sieht als Google
Ihre Website steht auf Seite eins bei Google. Der Traffic fließt stetig. Alles scheint in Ordnung. Doch wenn jemand ChatGPT oder Claude eine Frage zu Ihrer Branche stellt, taucht Ihr Unternehmen in der Antwort nirgends auf. Der Grund ist einfach: Der Zugriff von KI-Crawlern auf Websites funktioniert grundlegend anders als die klassische Indexierung durch Suchmaschinen. Was der Googlebot sieht und was KI-Systeme sehen, sind oft zwei sehr unterschiedliche Versionen Ihrer Seite.
Viele moderne Websites laden ihre Inhalte dynamisch nach – das bedeutet, Texte und Bilder erscheinen erst, nachdem Ihr Browser im Hintergrund Code ausgeführt hat. Sie sehen die fertige Seite, ein KI-Crawler oft nur eine leere Hülle. Hinzu kommt: Immer mehr Websites blockieren KI-Systeme aktiv (möglicherweise tut Ihre das auch, ohne dass Sie es wissen). Eine Analyse von Crawler-Beschränkungen aus 2025 zeigt, dass rund 25 % der 1.000 meistbesuchten Websites den Zugriff durch KI-Crawler einschränken – Nachrichten- und Medienseiten am aggressivsten.
Was der Googlebot kann, was ein KI-Crawler aber nicht kann
Um diesen Unterschied zu verstehen, müssen wir kurz über JavaScript sprechen. JavaScript ist eine Programmiersprache, die Websites interaktiv macht – sie steuert Dropdown-Menüs, Inhalte, die beim Scrollen nachladen, und Seiten, die sich aktualisieren, ohne neu geladen zu werden. Wenn Sie eine moderne Website besuchen, lädt Ihr Browser (Chrome, Safari, Firefox) die Seite herunter und führt anschließend JavaScript aus, um vieles von dem aufzubauen, was Sie tatsächlich auf dem Bildschirm sehen.
Google hat massiv in seinen Web Rendering Service (WRS) investiert – ein ausgeklügeltes System, das JavaScript ausführt und Seiten ähnlich wie Ihr Browser zusammenbaut. Dadurch sieht der Googlebot Ihre Website nahezu so, wie Sie sie beim Besuch sehen. Das Rendering von Google läuft für die meisten Seiten sehr schnell ab.
Den meisten KI-Crawlern fehlt diese Fähigkeit. Googles eigener KI-Crawler (auch von Gemini genutzt) ist eine Ausnahme und kann über den WRS rendern, doch die meisten anderen überspringen JavaScript komplett. JavaScript in großem Stil auszuführen erfordert enorme Rechenressourcen. Für Anbieter von Large Language Models (LLMs) – der Technologie hinter Werkzeugen wie ChatGPT – ist es schlicht nicht wirtschaftlich, Millionen von Seiten zu rendern. Sie nehmen, was sie schnell bekommen: das rohe HTML, das Ihr Server ausliefert, bevor irgendein JavaScript läuft. Stellen Sie sich das vor wie ein Rezept versus dem fertigen Gericht. Das Rezept (rohes HTML) enthält die Grundanweisungen, doch das fertige Ergebnis sehen Sie nur, wenn jemand diesen Anweisungen folgt (sprich: das JavaScript ausführt).
Die Realität für KI-Crawler: nur das rohe HTML
Die meisten KI-Crawler erfassen ausschließlich das, was in der ersten HTML-Antwort steht – also den Basiscode, den Ihr Server ausliefert, bevor der Browser irgendeine Arbeit erledigt. Dazu gehören Meta-Tags (versteckte Beschriftungen, die Ihre Seite beschreiben), Überschriftenstrukturen, statische Texte und Hyperlinks. Alles andere fällt weg.
Wenn KI-Werkzeuge Ihre Service-Seiten nicht lesen können, tauchen Sie nicht auf, sobald jemand ChatGPT bittet, Anbieter in Ihrer Kategorie zu vergleichen. Ihre Seite präsentiert menschlichen Besuchern reichhaltige, wertvolle Inhalte – während sie für KI-Bots, die nach indexierbarem Text suchen, fast leer wirkt.
Die JavaScript-Rendering-Lücke und ihre Folgen für KI-Crawler
Moderne Websites sind dynamisch. Sie bieten flüssige, App-ähnliche Erlebnisse, fühlen sich schnell und reaktionsfreudig an. Genau das schafft jedoch ein grundlegendes Problem für die KI-Sichtbarkeit, denn diese Seiten sind stark auf JavaScript angewiesen, um Inhalte überhaupt anzuzeigen.
Client-Side vs. Server-Side Rendering
Diese Unterscheidung ist wichtiger, als die meisten Geschäftsleitungen vermuten. Daher in einfachen Worten:
Client-Side Rendering bedeutet, dass der Browser des Besuchers (der „Client") die Hauptarbeit macht. Er lädt JavaScript herunter und baut den Seiteninhalt erst auf Ihrem Computer oder Smartphone zusammen. Vorteil: ein flüssiges, App-ähnliches Erlebnis. Nachteil: KI-Crawler sehen oft nicht das fertige Ergebnis, sondern nur die Rohzutaten vor dem Zusammenbau.
Server-Side Rendering bedeutet, dass Ihr Webserver die vollständige HTML-Seite aufbaut, bevor er sie an Besucher ausliefert. Trifft ein KI-Crawler auf Ihre Seite, bekommt er eine fertig zusammengebaute Seite mit allen Inhalten – ganz ohne Eigenarbeit. Nachteil: Ihr Server arbeitet mehr, was bei Lastspitzen Performance kosten kann.
Pre-Rendering ist ein verwandter Ansatz, bei dem Seiten im Voraus als komplette HTML-Dateien erzeugt werden, statt für jeden Besucher frisch zusammengebaut.
Warum Ihre moderne Website für die KI komplett leer sein könnte
Stellen Sie sich einen typischen E-Commerce-Shop vor, gebaut mit dynamischer, JavaScript-lastiger Technologie. Der Produktkatalog wird je nach Nutzerpräferenzen geladen. Kategorieseiten ziehen ihre Inhalte aus Datenbanken. Selbst die Navigation wird unter Umständen erst durch JavaScript im Browser aufgebaut. Für einen KI-Crawler erscheint diese hochentwickelte Seite als leere Hülle: vielleicht ein Logo, ein paar Footer-Links, sonst kaum etwas.
Das ist ein ernstes Problem – aber es gibt praktikable Lösungen. In diesem Artikel zeigen wir Ihnen, wie Sie testen, was ein Crawler tatsächlich sieht, und welche Schritte Sie unternehmen können, um Ihre Seiten ohne technische Generalüberholung lesbar zu machen.
Testen, was ein KI-Crawler tatsächlich sieht
Raten Sie nicht. In wenigen Minuten sehen Sie genau das HTML, das ein KI-Crawler von Ihren wichtigsten Seiten erhält. Diese Tests zeigen, ob Ihr Setup wirklich funktioniert.
Der „Seitenquelltext anzeigen"-Test
Klicken Sie mit der rechten Maustaste irgendwo auf Ihre Startseite und wählen Sie „Seitenquelltext anzeigen" (nicht „Element untersuchen" – das zeigt die fertige Seite nach dem JavaScript-Lauf). Damit sehen Sie das rohe HTML, bevor JavaScript irgendetwas tut. Suchen Sie nach Ihrem Firmennamen, Produktbeschreibungen oder zentralen Leistungen. Finden Sie sie hier nicht, finden KI-Crawler sie auch nicht.
Warnsignale sind Seiten, in denen der Body-Bereich nur aus Script-Tags (JavaScript-Anweisungen) und leeren Containern besteht. Erfolgreich sieht so aus: Alle Informationen, die ein KI-Crawler über Ihr Unternehmen kennen soll – Ihre Leistungen, Kontaktdaten, Kernangebote – stehen direkt im Quelltext.
JavaScript im Browser deaktivieren
Dieser Test simuliert, was die meisten KI-Crawler erleben. Drücken Sie in Chrome F12, um die Entwicklertools zu öffnen, dann Strg+Shift+P (oder Cmd+Shift+P am Mac) und tippen Sie „Disable JavaScript". Enter drücken, Seite neu laden.
Was übrig bleibt, ist das, was KI-Crawler sehen. Verschwindet Ihr Hauptinhalt, haben Sie ein Rendering-Problem. Aktivieren Sie JavaScript anschließend auf demselben Weg wieder.
Die robots.txt-Datei prüfen
Jede Website hat eine robots.txt – eine einfache Textdatei, die Crawlern sagt, worauf sie zugreifen dürfen und worauf nicht. Rufen Sie ihredomain.de/robots.txt direkt auf. Achten Sie auf Zeilen, die GPTBot, ClaudeBot, CCBot oder anthropic-ai erwähnen. Steht hinter einem dieser Namen „Disallow: /", blockieren Sie diese KI-Crawler aktiv. Hier ein Beispiel aus der robots.txt unseres KI-Schreibassistenten Skribt:
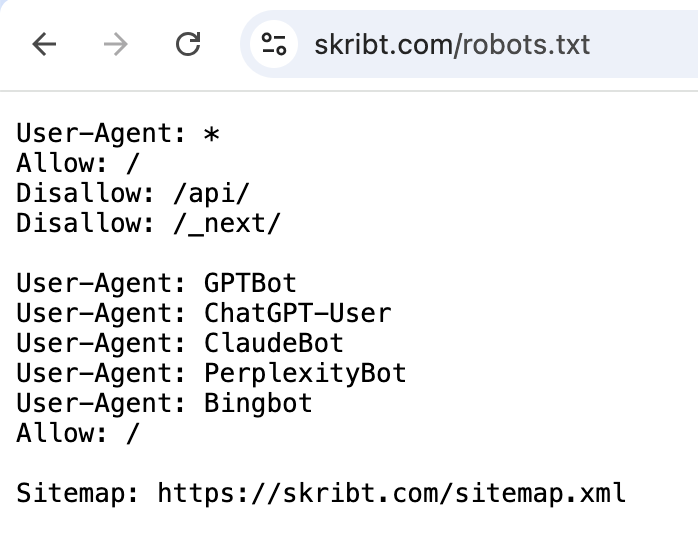
Manchmal ergänzen Hosting-Anbieter oder Sicherheits-Plugins solche Sperren ohne Ihr Wissen. Studien zeigen, dass 34,2 % der Nachrichtenanbieter mittlerweile OpenAIs GPTBot blockieren. Für die meisten Unternehmen bedeutet das Blockieren von KI-Bots aber, Sichtbarkeit in einem wachsenden Discovery-Kanal zu opfern.
Terminal-Befehl für rohes HTML
Wer mit der Kommandozeile vertraut ist (oder es ausprobieren möchte), bekommt mit diesem curl-Befehl genau das, was Crawler erhalten:
curl -A "Mozilla/5.0" https://ihrewebsite.de
Dieser Befehl lädt das rohe HTML Ihrer Seite herunter und zeigt es als Text an. Suchen Sie nach Ihren wichtigsten Inhalten. Tauchen Überschriften und Beschreibungen auf, ist Ihr HTML crawlerfreundlich. Sehen Sie hauptsächlich JavaScript-Verweise und leere Container, gibt es Arbeit.
Strukturierte Daten: Damit ein KI-Crawler Ihre Inhalte versteht
Selbst wenn KI-Crawler auf Ihre Inhalte zugreifen können, brauchen sie Kontext, um sie richtig einzuordnen. Strukturierte Daten liefern diesen Kontext über ein standardisiertes Vokabular, das Maschinen zuverlässig auswerten. Wenn Sie Systeme für Wissensmanagement oder Kunden-Tools bauen, gilt dasselbe Prinzip: Maschinen brauchen explizite Labels, um Informationen korrekt zu verarbeiten.
Was Schema-Markup wirklich ist
Schema-Markup ist eine Methode, Ihre Inhalte so zu beschriften, dass Maschinen verstehen, was sie bedeuten – und nicht nur, was wörtlich dasteht. Es nutzt ein standardisiertes Vokabular von Schema.org, das alle großen Suchmaschinen und KI-Systeme erkennen.
JSON-LD (JavaScript Object Notation for Linked Data) ist das empfohlene Format, weil es sich sauber in den Seitencode einfügt, ohne sich mit dem sichtbaren Inhalt zu vermischen. Sie können sich das wie ein unsichtbares Etikett vorstellen, das KI-Systemen sagt: „Diese Seite beschreibt ein Produkt mit diesem Preis, diesen Bewertungen und diesem Lagerstatus."
Strukturierte Daten helfen Suchmaschinen und KI, Ihre Website besser zu verstehen – sie machen es einfacher, Produkte, Standorte und FAQs richtig zu erfassen. Je größer die Rolle wird, die KI-Systeme bei der Entdeckung von Unternehmen spielen, desto wertvoller wird dieser maschinenlesbare Kontext.
Die wichtigsten Schema-Typen für Unternehmenswebsites
Vier Schema-Typen decken die meisten Anforderungen ab:
- Organization: Firmenname, Logo, Kontaktdaten und Social-Profile. Essenziell für die Markenwiedererkennung in KI-Antworten.
- Article: Für Blogposts und Nachrichten. Enthält Autor, Veröffentlichungsdatum und Headline. SEO-Plugins wie Yoast können das Schema für WordPress-Seiten generieren.
- Product: Preise, Verfügbarkeit, Bewertungen und Spezifikationen. Entscheidend für E-Commerce-Sichtbarkeit.
- FAQ: Frage-Antwort-Paare, die KI-Systeme direkt für Konversationsantworten extrahieren können.
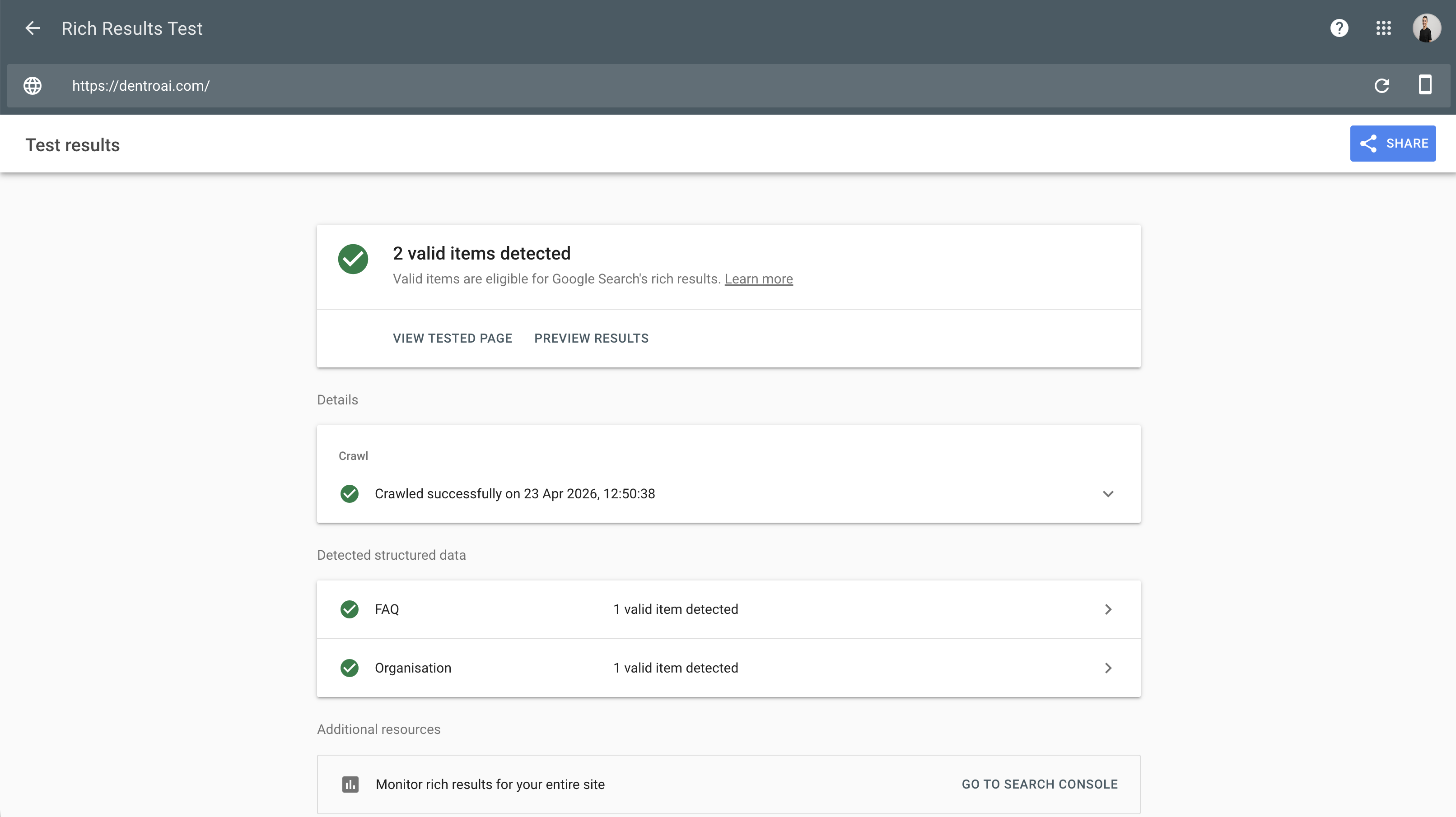
Validieren Sie Ihr Schema mit Googles Rich Results Test. URL einfügen – das Tool meldet, ob Ihre strukturierten Daten gültig sind und welche Typen erkannt wurden. Wer heute strukturierte Daten implementiert, bereitet seine Inhalte für künftige Technologien und KI-Anwendungen vor.
Ihre KI-Crawler-Checkliste (nicht-technisch)
Ihre Seite für KI-Bots sichtbar zu machen, erfordert sowohl schnelle Fixes als auch längerfristige technische Anpassungen. Zu wissen, was wozu gehört, hilft beim Priorisieren. Dieser Abschnitt fokussiert auf das Was, nicht das Warum – das haben wir oben behandelt.
Quick Wins, die Sie heute prüfen können
Beginnen Sie mit dem, was Sie sofort verifizieren können. Prüfen Sie Ihre robots.txt auf ungewollte KI-Crawler-Sperren. Führen Sie den View-Source-Test auf Ihren fünf wichtigsten Seiten durch. Deaktivieren Sie JavaScript und vergewissern Sie sich, dass Ihre Kerninhalte sichtbar bleiben. Zeigen die Tests Probleme, haben Sie konkrete Belege für Ihr Entwicklungsteam.
Auch die Server-Antwortzeit zählt. Nutzen Sie Googles PageSpeed Insights und achten Sie auf den TTFB-Wert (Time to First Byte) – er misst, wie schnell Ihr Server auf Anfragen zu reagieren beginnt. Ein hoher TTFB kann das Crawling weniger effizient machen und dazu führen, dass pro Besuch weniger Seiten abgeholt werden. Eine universelle Schwelle gibt es nicht, doch dauerhaft langsame Antworten (über einer Sekunde) verdienen genauere Untersuchung.
Stellen Sie Ihrem Entwicklungsteam diese konkreten Fragen:
- „Wie hoch ist unser durchschnittlicher TTFB auf Produkt- und Service-Seiten?"
- „Setzen wir Server-seitiges Caching ein und ist es für unsere Haupt-Templates konfiguriert?"
- „Hängen Seiten ausschließlich von clientseitigem JavaScript ab, um ihren Hauptinhalt zu rendern?"
- „Hat im letzten Jahr jemand die robots.txt geändert, und haben wir eine Versionshistorie?"
- „Können wir unsere Top-20-Seiten pre-rendern, ohne die ganze Website neu zu bauen?"
Gespräche, die Sie mit Ihrer Entwicklung führen sollten
Mit den Testergebnissen im Rücken können Sie diese Optionen mit dem Tech-Team besprechen. Server-Side Rendering oder Static Site Generation lösen Sichtbarkeitsprobleme durch JavaScript, wobei der Aufwand je nach Framework variiert. Strukturierte Daten erfordern in der Regel Entwicklerunterstützung, folgen aber gut dokumentierten Mustern. Fragen Sie gezielt nach Pre-Rendering kritischer Seiten, falls ein kompletter Site-Rebuild zu teuer erscheint. Ein Verständnis der Kosten eines KI-Projekts hilft, das Budget für solche technischen Verbesserungen zu planen.
Eine Sicherheitshinweis: Dokumentieren Sie vor größeren Änderungen Ihre aktuellen Suchrankings und Traffic-Muster. Technische Migrationen können kurzfristig zu Ranking-Einbußen führen. Eine Baseline hilft, Probleme schnell zu erkennen und zu beheben.
Fazit: Sichtbarkeit für KI-Crawler optimieren
Sichtbarkeit für Crawler hängt an drei Kernpunkten: JavaScript-gerenderte Inhalte, die Bots nicht sehen; robots.txt-Regeln, die Zugriff komplett blockieren; und fehlende strukturierte Daten, die KI helfen würden zu verstehen, was Ihre Seiten enthalten. Wenn Sie KI-Automatisierung breiter im Unternehmen ausloten, ist Ihre Web-Präsenz crawlerfit zu machen ein sinnvoller erster Schritt.
Was konkret passieren sollte:
- Quick Fixes: Führen Sie den View-Source- und den robots.txt-Test auf Ihren wichtigsten Seiten durch. Beheben Sie unbeabsichtigte Sperren und ergänzen Sie auf der Startseite Organization- und FAQ-Schema. Das sind Stunden, keine Tage.
- Größere Änderungen: Zeigen die Tests, dass JavaScript kritische Inhalte verbirgt, sprechen Sie mit Ihrer Entwicklung über Server-Side Rendering oder Pre-Rendering.
Wie schnell Sie das angehen, liegt an Ihnen und der Kapazität Ihres Teams. Manche Unternehmen erledigen alles an einem Wochenende. Andere arbeiten es nebenher ab. Entscheidend ist: Sie müssen Ihre Website nicht neu bauen – starten Sie mit den Tests, beheben Sie die offensichtlichen Sperren, ergänzen Sie ein Basis-Schema und kümmern Sie sich um Rendering-Probleme nur dort, wo die Tests echte Schwächen zeigen.
Wenn Sie eine zweite Meinung dazu möchten, wie sichtbar Ihre Seite für KI-Assistenten ist, melden Sie sich gerne jederzeit bei uns.